[Springboot + Redis] 레디스를 이용한 캐싱을 통해 API 성능 개선하기 ( +JMeter)
Github를 오마주한 3D model 버전 관리 웹 사이트를 만드는 프로젝트를 하던중 한가지 문제점을 발견했다.
유저가 Mypage에 들어갈때마다, 매번 내 정보 (닉네임, 이메일 , 팔로워 수, 팔로잉 수)를 받아오는 API와, 내 리포지토리 리스트를 불러오는 API를 매번 호출하게되어, 응답시간이 매우 느리다는 것이었다.
유저가 새로고침할때마다, API호출을 매번 하게되면 서비스가 성장하여 유저 트래픽이 많아지게되면 DB에 큰 부하가 가게 된다.
따라서 나는 처음에 Spring boot 프레임워크에서 자체적으로 지원하는 Cache 라이브러리를 사용해 , 서버의 로컬 메모리에서 캐싱을 하도록 구현하였다.
결과적으로 응답속도는 매우 빨랐다. 왜냐하면 서버 내부의 메모리에서 다이렉트로 접근하기 때문에, 속도차이가 확연 할 수 밖에 없었다.
하지만 이러한 서버 내부 메모리 캐싱 방식은, 결과적으로 서버가 여러대로 분산되었을때, 캐시값이 서로 일치하지 않는다는 문제가 발생한다.
이 프로젝트에서는 서버 내부 캐시를 이용해도 되었지만, 캐시의 정합성을 보장해주는 방식인, 외부 서버를 이용하는 Redis 캐싱 방식을 이용하기로 하였다.
Redis 외부 캐싱방식을 도입하면, 결국엔 Redis도 하나의 서버이기때문에 그곳으로 네트워크 요청을 보내는 오버헤드가 발생한다.
따라서 서버 내부 인메모리 캐시방식보다는 현저히 속도가 차이가나지만, 중요한 데이터의 정합성을 위해서는 외부 캐싱 방식을 사용해야만 한다.
https://kjs990114.tistory.com/66
[Redis] Redis에 대해서 알아보기
Redis란? Redis란 'Remote Dictionary Server'의 줄임말로 key-value 구조의 데이터를 인메모리에 저장하는 오픈소스 데이터 관리 시스템 입니다. Redis는 데이터를 인메모리에 저장하기때문에 처리 속도가 기
kjs990114.tistory.com
기존 서비스 로직
@Transactional(readOnly = true)
public Page<PostDTO.Summary> getPosts(Long userId, int page, boolean isMyPosts) {
Pageable pageable = PageRequest.of(page, pageSize, Sort.by("lastModifiedAt").descending());
Page<Post> entityPage = isMyPosts ? postRepository.findUserPublicAndPrivatePosts(userId, pageable) : postRepository.findUserPublicPosts(userId, pageable);
RestPage<PostDTO.Summary> dbPage = new RestPage<>(entityPage.map(DTOMapper::postToSummary));
return dbPage;
}
서비스 로직이 실행되면, JPA 리포지토리에서 db에 접근하여 Page<Post>를 반환하고, 이를 Controller가 바로 받아서 사용할 수 있게 Page<PostDTO>로 변환후 반환한다.
수정 후 서비스 로직
@Transactional(readOnly = true)
public RestPage<PostDTO.Summary> getPosts(Long userId, int page, boolean isMyPosts) {
HashOperations<String, String, RestPage<PostDTO.Summary>> hashOp = redisTemplate.opsForHash();
String key = cacheName + ":" + userId;
String hashKey = page + ":" + isMyPosts;
RestPage<PostDTO.Summary> cachedPage = hashOp.get(key, hashKey);
if (cachedPage != null) {
return cachedPage;
}
Pageable pageable = PageRequest.of(page, pageSize, Sort.by("lastModifiedAt").descending());
Page<Post> entityPage = isMyPosts ? postRepository.findUserPublicAndPrivatePosts(userId, pageable) : postRepository.findUserPublicPosts(userId, pageable);
RestPage<PostDTO.Summary> dbPage = new RestPage<>(entityPage.map(DTOMapper::postToSummary));
hashOp.put(key,hashKey,dbPage);
return dbPage;
}
나는 키를 userId 로 동적으로 생성하고, 서브키를 page + isMyPosts로 분리하여 캐시를 생성하고 싶었다.
하지만 @Cacheable 어노테이션은 기본적으로 ValueOperation만을 지원하기떄문에,복잡한 키/값 설정이 불가능했다.
왜냐하면, 현재 내 캐싱 전략은
page와 isMyposts값에따라서 캐싱하는 데이터가 다르고(isMyPosts가 참이면, private 리포지토리도 보여줘야 하기때문)
또한 가장 큰 이유는 나중에 cache를 지울때 편리하기 때문이다.(user의 post가 create, update, delete되면, userId로 구성되는 메인키만을 이용하여 cache를 전부 지우면 된다.)
따라서 HashOperation방식을 사용해야 하기때문에 어노테이션이아닌, 비즈니스 로직에 코드를 적는 방식으로 캐시를 구현하였다.
먼저 redisTemplate을 통해 cache가 있는지 확인후, 있다면 그것을 return하면되고, 없다면 기존 로직을 이용해 database에서 데이터를 불러와, 캐시에 넣은후 반환한다.
또한 아래와 같이 캐시의 정합성을 위해, post가 create, delete, update될때 restTemplate.delete(key)를 사용해주어 cache를 evict시켰다.
@Transactional
public void createPost(PostDTO.Create create, Long userId) throws IOException {
/**
게시글 생성 로직
**/
redisTemplate.delete(cacheName + ":" + userId);
}
@Transactional
public void deletePost(Long postId) {
Post post = postRepository.findByPostId(postId).orElseThrow(() -> new NotFoundException("Post does not exist"));
User user = post.getUser();
/**
게시글 삭제 로직
**/
redisTemplate.delete(cacheName + ":" + user.getUserId());
}
@Transactional
public void updatePost(Long postId, PostDTO.Update update) throws IOException {
Post post = postRepository.findByPostId(postId).orElseThrow(() -> new NotFoundException("Post does not exist"));
User user = post.getUser();
/**
게시글 업데이트 로직
**/
redisTemplate.delete(cacheName + ":" + user.getUserId());
}
그 결과 응답이 체감상 빨라진것 같긴 하나, 이를 JMeter를 통해 더 정확히 성능을 비교해보기로 하였다.
쓰레드 그룹

쓰레드 그룹은 100으로, 100명의 유저를 가정하였고 loop는 10회 반복하여 1000번의 요청을 할 예정이다.
HTTP Sampler

http는 단순히 유저의 포스트를 조회하는 api이며, 로컬 서버에서 돌리면 메모리를 공유하고, 단일 인스턴스로 돌리기때문에 부정확한 결과가 나오기 때문에 실제로 배포한 백엔드 url을 이용하였다.
또한 userId는 랜덤으로 설정하였다.
결과
캐싱을 사용하기 전
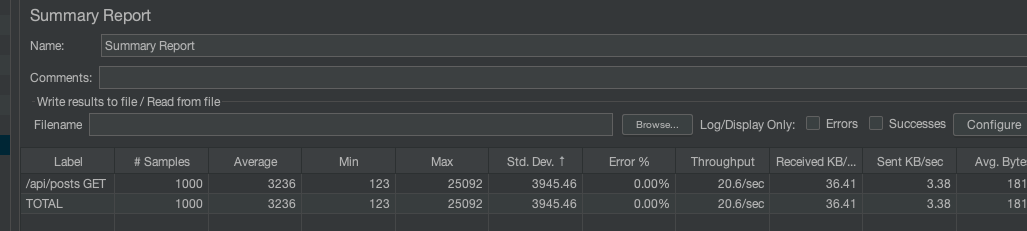
갑자기 900번대의 요청에서 서버 부하가 걸리더니 MAX가 25초나 걸리는 끔찍한 상황이 발생하였다.
또한 평균 응답 시간은 3.2초로 매우느리다.
Redis를 적용한 후

평균 응답속도는 0.8초로, 무려 4배나 빨라진 속도를 확인 할 수 있었고, 75%의 속도 향상을 이루어 낼 수 있었다
더 고민해 보아야 할 점
캐싱을 활용하기 가장 적합한 리소스는
1. 자주 노출되고
2. 자주 변하지 않는
리소스가 제일 적합하다고 하였다.
하지만 지금 내 캐싱전략은 1번만 만족한다.

왜냐하면 로그인을 진행하면 기본으로 보는 페이지가 위와 같은 mypage (깃허브를 모방) 이기때문에,
유저가 제일 자주 마주하는 페이지이기 떄문이다.
하지만 repository는 2번조건을 전혀 만족하지못한다.
사소하게 update, commit만 해도 이것을 UPDATE라고 간주해, 해당 user의 repository list cache를 전부 evict하기 때문이다.
(심지어 like만 눌러도 cache를 evict해버린다)
그리고 형상관리 서비스의 특성상 commit하는 경우가 굉장히 많을것이기때문에 리소스의 변화주기가 짧다면 짧다고 할수있다.
그렇게되면 대규모 서비스로 발전하였을때, Redis에서 캐시를 삭제하고 다시 갱신하는 오버헤드가 오히려 캐시를 통해 얻는 이득보다 커질 수 있다는 부담이 있다.
하지만, 그럼에도 내가 해당 리소스에 캐시를 사용한 이유는
결과적으로는 해당 페이지를 조회하는 횟수가, 수정하는 횟수보다 많을것이라고 생각하기 때문이다.
3D모델의 특성상, 코드와는 달리 수정후 commit하는 주기가 상대적으로 길다고 생각하기떄문이었다.