독서광 동철이는 책을 정말 꼼꼼히 읽는다. 그 증거로, 책에서 어떤 단어가 몇 번 등장하는지 물어보면 정확하게 그 답을 맞춰내는 신기한 능력이 있다.
그런데, 특출난 능력이 있으면 누군가는 시샘을 하게 마련이다.
동철이의 친구 영수는 동철이의 이런 능력을 의심하고 있었지만, 도저히 그 답이 맞는지 세어볼 수가 없어 당신에게 도움을 요청하였다.
영수의 궁금증을 해소해주기 위하여, 책의 내용 B가 주어질 때 특정 단어 S가 등장하는 횟수를 알아내어라.
책의 내용에서 특정 단어가 등장하는 부분이 중첩될 수도 있음에 유의하여라.
예를 들어, B="ABABA"이고 S="ABA"이면 2번 등장하는 것으로 간주한다.
[입력]
첫 줄에 테스트케이스의 개수 T가 주어진다. (1 ≤ T ≤ 20)
각 테스트 케이스의 첫 번째 줄에 책의 내용 B가 주어진다.
책의 내용은 알파벳 소문자와 대문자, 그리고 숫자로만 이루어지고, 길이는 1 이상 500,000 이하이다.
각 테스트 케이스의 두 번째 줄에 찾고자 하는 단어 S가 주어진다.
찾고자 하는 단어는 알파벳 소문자와 대문자, 그리고 숫자로만 이루어지고, 길이는 1 이상 100,000 이하이다.
[출력]
각 테스트케이스마다 한 줄에 걸쳐, 테스트케이스 수 “#(TC) “를 출력하고, 단어가 등장하는 횟수를 출력한다.
풀이과정
처음에는 완전탐색으로 일일히 비교해주었으나
시간복잡도 O(N^2)이므로
500,000 * 100,000 = 500억 이기때문에
시간초과로 주어진 시간내에 풀 수 없었다
접미사 트라이를 이용해 부분문자열을 검사하는 방법도있겠으나
접미사 트라이를 만드는 과정이 O(n^2)이라 시간초과가 나니 패스
이문제는 KMP 알고리즘으로 풀 수있으나
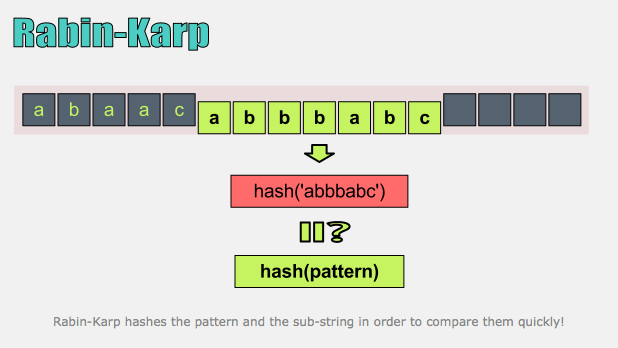
해쉬를 이용한 라빈 카프( Rabin- Karp) 알고리즘을 이용해 풀었다
라빈 카프 알고리즘
출처 : https://dzone.com/articles/algorithm-week-rabin-karp
Algorithm of the Week: Rabin-Karp String Searching - DZone Java
Brute force string matching is a very basic sub-string matching algorithm, but it’s good for some reasons. For example it doesn’t require preprocessing of the...
dzone.com
라빈 카프 알고리즘이란 연속되는 문자열의 해쉬값을 구하고,
Target이 되는 해쉬값과 하나하나 비교하는 알고리즘이다.
시간복잡도는 O(n)이라고 한다.
주어진 문자열이 ABCDEFG라고하고
그 문자열에서 CD를 찾고자할때,
AB의 해쉬값과 CD의 해쉬값을비교한다.
한칸 건너뛰어 BC의 해쉬값과 CD비교
CD와 CD비교 -> 일치
여기서 궁금증이 결국 해쉬값을 구하는과정에서 O(n)의 시간복잡도를 가지므로
O(n *m)의 시간복잡도가 되지않을까? 라는 의문이 들었는데
해쉬값을 구하는 과정이 O(1)이다.
처음 AB의 해시값을 구해서 비교한 다음에 다음 문자인 BC로 이동할 때, BC의 해시값을 처음부터 구하는 것이 아니라, AB의 해시값에서 제거되는 A에 해당하는 해시값만 빼주고, 추가되는 C에 해당하는 해시값을 더해주어서 BC의 해시값을 구하게 되는 것이기 때문에
빼주고 , 더해주는 연산 두개만 해주면되므로 O(1)이 되는것이다.
(단 맨처음 AB의 해쉬값은 일일히 구해주는 과정이 필요하긴 하다)
원래같으면 주어진 문자열을 처음부터 끝까지 패턴과 비교하면서 해시값을 구하는데, 중복되는 부분의 해시값은 그대로 두고 업데이트되는 부분만 해시값을 계산해주어서 중복되는 연산을 줄일 수 있다는 것이다.
이것을 Rolling Hash라고 한다.
라빈 카프 알고리즘에서는 Rabin fingerprint라는 rolling hash function을 사용합니다.

위 식과 같은 형태를 띄고 있는데, m은 문자열의 각 자리에 해당하는 문자이며 보통 아스키코드를 많이 사용합니다. x는 무엇이든 상관없지만, 보통 2를 사용합니다.
따라서 'abr'라는 문자열의 해시값을 구하면 다음과 같습니다.(a의 ASCII : 97, b의 ASCII : 98, r의 ASCII : 114)
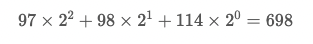
(m_0가 가장 오른쪽의 문자이므로 순서에 주의)
그렇다면 비교할 문자열이 'bra'로 변경되면, 이 문자열의 해시값은 어떻게 될까요?
위 식을 사용해서 구하면 다음과 같습니다.
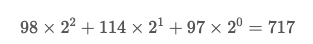
하지만, 실제로 이렇게 처음부터 구하지 않습니다.
우리는 이전 문자열 'abr'에서 'bra'로 변경되었을 때, 'br'이라는 문자가 중복된다는 것을 알고 있습니다. 따라서, rolling hash의 특징을 사용해서 중복된 이전 문자열에서 제거되는 'a'에 해당하는 해시값만 빼주고 2를 곱해준 다음, 추가되는 문자열 'a'의 해시값을 더해주면 됩니다.
기존 문자열 'abr'의 해시값은 698이고, 제거되는 'a'의 해시값은 97 \times 2^2 = 388 입니다.
따라서, 698 - 388 = 310이 되며, b의 위치가 처음 위치가 되므로 2를 곱해주면 310 x 2 = 620이 됩니다.
마지막으로 추가되는 'a'의 해시값을 더해주면 620 + 97 = 717이 우리가 구하는 'bra'의 해시값이 됩니다.
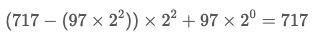
주어진 문자열의 구성요소는
숫자 , 대소문자이므로
'0' ~ '9'
'a' ~'z'
'A' ~'Z'
총 10 + 26 + 26 = 62개이므로
62와 가장 가까운소수 67을 Hash값으로 하여 해쉬 충돌을 최대한 피해주었다.
그리고
'0' ~ '9'
'a' ~'z'
'A' ~'Z'
의 아스키코드값이 제각각 불연속적으로 떨어져있기에
이를 0 ~62의 연속된 값으로 압축시키기위한 메소드 getUnicode(char c)도 추가해주었다
('0'은 1반환 , '9'는 10 반환 , 'a'는 11반환, 'Z' 는 63반환 )
(솔직히 이과정이 필요하는지는 잘 모르겠다. 그냥 해달 문자의 char값을 그대로 쓰면 되지 않나 싶은데
라빈카프 알고리즘이라는게 해쉬충돌이 발생할 가능성이 있으므로 좀 더 확실히 하고자 그냥 이과정을 진행했다)
그리고 해쉬값 저장변수를 long (64bit)로 선언하여 해쉬충돌을 최대한 피해주었다.
그 이후에는 라빈 -카프 알고리즘에 의해 해쉬값을 구해주었다.
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class Solution {
public static void main(String[] args) throws Exception {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int TC = Integer.parseInt(br.readLine());
for (int i = 1; i <= TC; i++) {
String bookString = br.readLine();
String findString = br.readLine();
long findHash = hash(findString,findString.length());
System.out.println(findHash);
int count = 0;
long targetHash = hash(bookString,findString.length());
long offset = 1;
for (int k = 0; k < findString.length() - 1; k++) {
offset *= 67;
}
for (int k = 0; k < bookString.length() - findString.length(); k++) {
if (findHash == targetHash) {
count++;
}
targetHash = (targetHash - getUnicode(bookString.charAt(k)) * offset) * 67
+ getUnicode(bookString.charAt(k + findString.length()));
}
if (findHash == targetHash) {
count++;
}
System.out.println("#" + i + " " + count);
}
}
public static int getUnicode(char c) {
if(c>= '0' && c<='9') return c - 48;
if(c >= 'a' && c<= 'z') return c-87;
else return c - 65 + 36;
}
public static long hash(String str, int length) {
long hash = 0;
for (int i = 0; i < length; i++) {
hash = hash * 67 + getUnicode(str.charAt(i));
}
return hash;
}
}
'PS > 기타 알고리즘' 카테고리의 다른 글
| [JAVA] 백준 27172 - 수 나누기 게임 (에라토스 테네스의 체) (0) | 2024.10.13 |
|---|